Nghiên cứu mới của Apple cho thấy các mô hình AI mô phỏng tư duy, như OpenAI o1, o3 và Claude 3.7 Sonnet Thinking, chủ yếu dựa vào lặp lại mẫu từ dữ liệu đã thấy thay vì 'suy luận' thật. Nhóm tiến hành các thử nghiệm trên các câu đố kinh điển, chỉ ra mô hình AI giảm hiệu suất đáng kể với các bài toán mới và phức tạp.
Apple nghiên cứu giới hạn của AI mô phỏng tư duy
Đầu tháng 6/2024, nhóm nghiên cứu của Apple do Parshin Shojaee và Iman Mirzadeh chủ trì, công bố báo cáo "The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity" (Ảo tưởng về tư duy: Hiểu về sức mạnh và hạn chế của mô hình tư duy qua lăng kính độ phức tạp bài toán).
Nhóm tập trung vào các "large reasoning models" (LRMs - mô hình suy luận lớn), vốn mô phỏng quá trình suy diễn nhờ tạo ra chuỗi giải thích (chain-of-thought reasoning) nhằm giải quyết các bài toán từng bước một.
Chi tiết thử nghiệm: Đặt AI trước những thử thách tư duy kinh điển
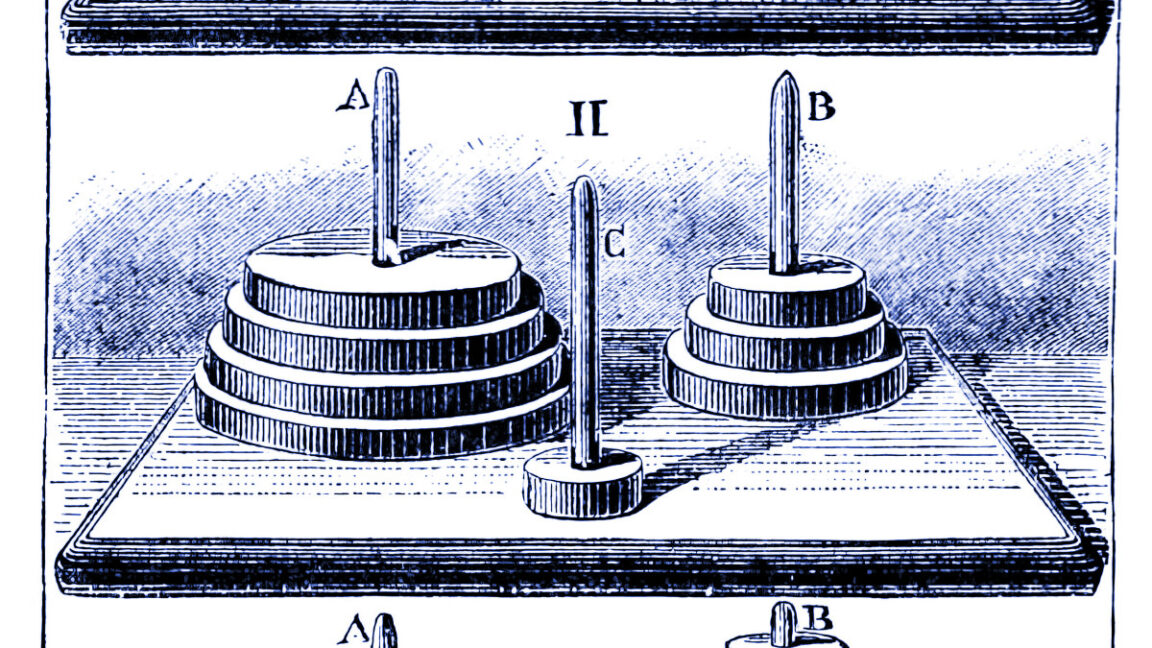
- Sử dụng 4 câu đố cổ điển: Tower of Hanoi, jump checker, river crossing, blocks world
- Bài toán được tăng dần độ khó: từ cực dễ (1 disk Hanoi) đến cực khó (20 disk Hanoi, cần hơn 1 triệu bước)
- So sánh hiệu quả giữa mô hình SR (simulated reasoning) như OpenAI o1/o3, Claude 3.7 Sonnet với mẫu tiêu chuẩn như GPT-4o
Kết quả: Dấu hỏi về khả năng "tư duy" thực sự của AI
Kết quả nghiên cứu gần giống như khảo sát của USAMO hồi tháng 4/2024: Hầu hết mô hình chỉ đạt dưới 5% điểm trên các đề toán mới cần chứng minh, duy nhất một trường hợp đạt 25%, không có nghiệm hoàn hảo trong gần 200 lần thử.
- AI có thể giải tốt các bài toán đơn giản, nhưng hiệu năng tụt mạnh với các bài cực khó
- Mô hình simulated reasoning 'suy luận quá mức' dẫn đến trả lời sai ở bài dễ
- Dù được cung cấp thuật toán giải Tower of Hanoi, model vẫn không cải thiện
- Xuất hiện "counterintuitive scaling limit" (ngưỡng tỷ lệ ngược) – càng phức tạp, càng ít dùng 'token' để suy luận hơn
- Một số mô hình nhất quán sai ở những dạng bài khác nhau, như Claude 3.7 Sonnet toi đến 100 nước của Tower of Hanoi nhưng thất bại với river crossing chỉ sau 5 bước
Tranh cãi trong cộng đồng AI: Lỗi hệ thống hay quyết định thiết kế?
Phản biện và đa chiều ý kiến chuyên gia
Gary Marcus, nhà nghiên cứu AI lâu năm, gọi kết quả của Apple là "đòn nặng" cho danh tiếng các mô hình LLM, nhấn mạnh chúng chỉ lặp lại mẫu thay vì tư duy hệ thống. Tuy nhiên, chuyên gia như Kevin A. Bryan (ĐH Toronto) cho rằng đây có thể chỉ là giới hạn do cố tình đặt ra trong huấn luyện RL (Reinforcement Learning), còn thực tế hiệu năng nhiều bài toán sẽ tiếp tục tăng nếu cho phép model tăng lượng token suy nghĩ.
Kỹ sư phần mềm Sean Goedecke và nhà nghiên cứu độc lập Simon Willison cũng đặt câu hỏi về độ phù hợp của các bài kiểm tra kiểu này với AI hiện đại, gợi ý giới hạn có thể xuất phát từ dung lượng context window (khung văn bản tối đa mà AI xử lý) thay vì bản chất của mô hình.
Nhóm Apple khẳng định kết luận chỉ giới hạn trong phạm vi khảo sát
Bản thân nhóm tác giả Apple cho biết môi trường thử nghiệm "là một phần rất nhỏ trong các tác vụ suy luận thực tế". Các mô hình AI vẫn có cải thiện rõ rệt trong "vùng bài toán trung bình" và tiếp tục hữu ích ở một số ứng dụng ngoài đời thực.
Ý nghĩa với lĩnh vực AI và cộng đồng khoa học
Cảnh báo và hướng ứng dụng thực tế
Kết hợp kết quả của Apple với USAMO khiến lập luận của các nhà phê bình như Marcus thêm vững chắc: hiện tại, AI suy luận phần lớn nhờ phát hiện, bắt chước mẫu có sẵn trong dữ liệu huấn luyện chứ chưa đạt tới tư duy hệ thống. Tuy nhiên, cả hai nghiên cứu đều khẳng định AI vẫn hữu dụng ở các tác vụ như lập trình, brainstorming, sáng tác văn bản... miễn là người dùng hiểu nhược điểm của nó.
Nghiên cứu của Apple hé mở các giới hạn về khả năng 'suy luận' của mô hình AI khi đứng trước thử thách mới ngoài dữ liệu huấn luyện. Tuy nhiên, AI vẫn giữ vai trò quan trọng trong nhiều ứng dụng hiện nay, nếu hiểu và sử dụng đúng khả năng thực tế của chúng.